Note
This tech note contains technology investigations done in the period 2007 to 2013. The first three sections were originally published in [2] and subsequently [4] (see DocuShare version 18). Document LDM-135 no longer contains the historical background and the content has been migrated to different locations. 4 Experiments on Hive is originally from LSST Trac and was referenced from LDM-135.
1 Potential Solutions - Research¶
The two most promising technologies able to scale to LSST size available today are Relational Database Management Systems (RDBMS) and Map/Reduce (MR): the largest DBMS system, based on commercial Teradata and reaching 20+ petabytes is hosted at eBay, and the largest MR-based systems, reaching many tens of petabytes are hosted at Google, Facebook, Yahoo! and others.
1.1 The Research¶
To decide which technology best fits the LSST requirements [41], we did an extensive market research and analyses, reviewed relevant literature, and run appropriate stress-tests for selected “promising” candidates, focusing on weak points and the most uncertain aspects. Market research and analyses involved (a) discussions about lessons learned with many industrial and scientific users dealing with large data sets, (b) discussions about existing solutions and future product road-maps with leading solution providers and promising start-ups, and (c), research road-map with leading database researchers from academia. See 5 People/Communities We Talked To.
1.2 The Results¶
As a result of our research, we determined an RDBMS-based solution involving a shared-nothing parallel database is a much better fit for the LSST needs than MR. The main reasons are availability of indexes which are absolutely essential for low-volume queries and spatial indexes, support for schemas and catalogs, performance and efficient use of resources.
Even though a suitable open source off-the-shelf DMBS capable of meeting LSST needs does not exist today, there is a good chance a system meeting most of the key requirements will be available well before LSST production starts. In particular, there are two very promising by-products of our research:
- we co-initiated [1], co-founded, and helped bootstrap SciDB – a new open source shared nothing database system, and
- we pushed the development of MonetDB, an open source columnar database into directions very well aligned with LSST needs. We closely collaborate with the MonetDB team – building on our Qserv lessons-learned, the team is trying to add missing features and turn their software into a system capable of supporting LSST needs. In 2012 we demonstrated running Qserv with a MonetDB backend instead of MySQL.
Both SciDB and MonetDB have strong potential to become the LSST database solution once they mature.
Further, our research led to creation a new, now internationally-recognized conference series, Extremely Large Databases (XLDB). As we continue leading the XLDB effort, it gives us a unique opportunity to reach out to a wide range of high-profile organizations dealing with large data sets, and raise awareness of the LSST needs among researchers and developers working on both MR and DBMS solutions.
The remaining of this chapter discusses lessons learned to-date, along with a description of relevant tests we have run.
1.3 Map/Reduce-based and NoSQL Solutions¶
Map/Reduce is a software framework to support distributed computing on large data sets on clusters of computers. Google’s implementation [10], believed to be the most advanced, is proprietary, and in spite of Google being one of the LSST collaborators, we were unable to gain access to any of their MR software or infrastructure. Additional Google-internal MR-related projects include BigTable [7], Chubby [6], and Sawzall [29]. BigTable addresses the need for rapid searches through a specialized index; Chubby adds transactional support; and Sawzall is a procedural language for expressing queries. Most of these solutions attempt to add partial database-like features such as schema catalog, indexes, and transactions. The most recent MR developments at Google are Dremel [22] - an interactive ad-hoc query system for analysis of read-only data, and Tenzing – a full SQL implementation on the MR Framework [8]. [1]
| [1] | Through our XLDB efforts, Google provided us with a preprint of a Tenzing manuscript accepted for publication at VLDB 2011. |
In parallel to the closed-source systems at Google, similar open-source solutions are built by a community of developers led by Facebook, Yahoo! and Cloudera, and they have already gained wide-spread acceptance and support. The open source version of MR, Hadoop, has became popular in particular among industrial users. Other solutions developed on top (and “around”) Hadoop include HBase (equivalent of BigTable), Hive (concept similar to Google’s Dremel), Pig Latin (equivalent to Google’s Sawzall), Zookeeper (equivalent to Google’s Chubby), Simon, and others. As in Google’s case, the primary purpose of building these solutions is adding database-features on top of MR. Hadoop is commercially supported by Cloudera, Hortonworks [Yahoo] and Hadapt.
We have experimented with Hadoop (0.20.2) and Hive (0.7.0) in mid 2010 using a 1 billion row USNO-B data set on a 64 node cluster (see 4 Experiments on Hive for more details). Common LSST queries were tested, ranging from low-volume type (such as finding a single object, selecting objects near other know object), through high-volume ones (full table scans) to complex queries involving joins (join was implemented in a standard way, in the reduce step). The results were discussed with Hadoop/Hive experts from Cloudera. Periodically we revisit the progress and feature set available in the Hadoop ecosystem, but to date we have not found compelling reasons to consider Hadoop as a serious alternative for managing LSST data.
Independently, Microsoft developed a system called Dryad, geared towards executing distributed computations beyond “flat” Map and Reduce, along with a corresponding language called LINQ. Due to its strong dependence on Windows OS and limited availability, use of Dryad outside of Microsoft is very limited. Based on news reports [14], Microsoft dropped support for Dryad back in late 2011.
Further, there is a group of new emerging solutions often called as NoSQL. The two most popular ones are MongoDB and Cassandra.
The remaining of this section discusses all of the above-mentioned products.
Further details about individual MR and no-SQL solutions can be found in 2 Map/Reduce Solutions and 3 Database Solutions.
1.4 DBMS Solutions¶
Database systems have been around for much longer than MR, and therefore they are much more mature. They can be divided into many types: parallel/single node, relational/object-oriented, columnar/row-based; some are built as appliances. Details about individual DBMS products and solutions we considered and/or evaluated can be found in 3 Database Solutions.
1.4.1 Parallel DBMSes¶
Parallel databases, also called MPP DBMS (massively parallel processing DBMS), improve performance through parallelization of queries: using multiple CPUs, disks and servers in parallel. Data is processed in parallel, and aggregated into a final result. The aggregation may include computing average, max/min and other aggregate functions. This process is often called scatter-gather, and it is somewhat similar to map and reduce stages in the MR systems.
Shared-nothing parallel databases, which fragment data and in many cases use an internal communications strategy similar to MR, scale significantly better than single-node or shared-disk databases. Teradata uses proprietary hardware, but there are a number of efforts to leverage increasingly-fast commodity networks to achieve the same performance at much lower cost, including Greenplum, DB2 Parallel Edition, Aster Data, GridSQL, ParAccel, InfiniDB, SciDB, and Project Madison at Microsoft (based on DATAllegro, acquired by Microsoft in 2008). Most of these efforts are relatively new, and thus the products are relatively immature. EBay’s installation used to be based on Greenplum in 2009 and reached 6.5 PB, but their current Singularity system is now approaching 30 PB and is based on Teradata’s appliances. Some of these databases have partition-wise join, which can allow entity/observation join queries to execute more efficiently, but none allow overlapping partitions, limiting the potential performance of pairwise analysis.
Microsoft SQL Server offers Distributed Partitioned Views, which provide much of the functionality of a shared-nothing parallel database by federating multiple tables across multiple servers into a single view. This technology is used in the interesting GrayWulf project [33] [31] which is designed to host observational data consisting of Pan-STARRS PS1 [42] astronomical detections and summary information about the objects that produced them. GrayWulf partitions observation data across nodes by “zones” [15], but these partitions cannot overlap. Fault tolerance is built in by having three copies of the data, with one undergoing updates – primarily appending new detections – and the other two in a hot/warm relationship for failover. GrayWulf has significant limitations, however. The object information for the Pan-STARRS PS1 data set is small enough (few TB) that it can be materialized on a single node. The lack of partition-wise join penalizes entity/observation join queries and pairwise analysis. The overall system design is closely tied to the commercial SQL Server product, and re-hosting it on another RDBMS, in particular an open source one, would be quite difficult.
The MPP database is ideal for the LSST database architecture. Unfortunately, the only scalable, proven off-the-shelf solutions are commercial and expensive: Teradata, Greenplum. Both systems are (or recently were) behind today world’s largest production database systems at places such as eBay [24] [25] and Walmart [30]. IBM’s DB2 “parallel edition”, even though it implements a shared-nothing architecture since mid-1990 focuses primarily on supporting unstructured data (XML), not large scale analytics.
The emergence of several new startups, such as Aster Data, DataAllegro, ParAccel, GridSQL and SciDB is promising, although some of them have already been purchased by the big and expensive commercial RDBMSes: Teradata purchased Aster Data, Microsoft purchased DataAllegro. To date, the only shared-nothing parallel RDBMS available as open source is SciDB – its first production version (v11.06) was released in June 2011. ParAccel is proprietary, we did not have a chance to test it, however given we have not heard of any large scale installation based on ParAccel we have doubts whether it’ll meet our needs. After testing GridSQL we determined it does not offer enough benefits to justify using it, the main cons include limited choices of partitioning types (hash partitioning only), lack of provisions for efficient near neighbor joins, poor stability and lack of good documentation.
SciDB [9] is the only parallel open source DBMS currently available on the market. It is a columnar, shared-nothing store based on an array data model. The project has been inspired by the LSST needs, and the LSST Database team is continuously in close communication with the SciDB developers. SciDB’s architectural features of chunking large arrays into overlapping chunks and distributing these chunks across a shared nothing cluster of machines match the LSST database architecture. Initial tests run with the v0.5 SciDB release exposed architectural issues with SciDB essential for LSST, related to clustering and indexing multi-billion, sparse arrays of objects in a 2-dimensional (ra, declination) space. These issues have been addressed since then and re-testing is planned.
There are several reasons why SciDB is not our baseline, and we currently do not have plans to use it for LSST catalog data. First, as an array database, SciDB uses a non-SQL query language (actually, two) appropriate for arrays. Adapting this to SQL, likely through a translation layer, is a substantial burden, even more difficult than parsing SQL queries for reissue as other SQL queries. (Given the widespread use of SQL in the astronomy community and the ecosystem of tools available for SQL, moving away from SQL would be a major endeavor.) Second, while relations can be thought of as one-dimensional arrays, SciDB is not optimized to handle them as well as a traditional RDBMS, in particular for the variety of joins required (including star schema, merge joins, and self joins). Standard RDBMS features like views, stored procedures, and privileges would have to be added from the ground up. Third, SciDB’s fault tolerance is not yet at the level of XRootD. Overall, the level of coding we would have to do to build on the current SciDB implementation appears to be larger than what we are planning on top of XRootD/MySQL. As SciDB’s implementation progresses, though, this trade-off could change.
1.4.2 Object-oriented solutions¶
The object-oriented database market is very small, and the choices are limited to a few small proprietary solutions, including Objectivity/DB and InterSystems Caché. Objectivity/DB was used by the BaBar experiment in 1999 – 2002, and the BaBar database reached a petabyte [5]. The members of LSST database team, being the former members of the BaBar database team are intimately familiar with the BaBar database architecture. The Objectivity/DB was used primarily as a simple data store, all the complexity, including custom indices had to be all built in custom, user code. Given that, combining with the challenges related to porting and debugging commercial system led as to a conclusion Objectivity/DB is not the right choice for LSST.
InterSystems Caché has been chosen as the underlying system for the European Gaia project [39] [40], based on our limited knowledge, so far the Gaia project focused primarily on using Caché for ingest-related aspects of the system, and did not have a chance to research analytical capabilities of Caché at scale.
1.4.3 Row-based vs columnar stores¶
Row-based stores organize data on disk as rows, while columnar store – as columns. Column-store databases emerged relatively recently, and are based on the C-store work [32]. By operating on columns rather than rows, they are able to retrieve only the columns required for a query and greatly compress the data within each column. Both reduce disk I/O and hence required hardware by a significant factor for many analytical queries on observational data that only use a fraction of the available columns. Current column stores also allow data to be partitioned across multiple nodes, operating in a shared-nothing manner. Column stores are less efficient for queries retrieving small sets of full-width records, as they must reassemble values from all of the columns.
Our baseline architecture assumes all large-volume queries will be answered through shared scans, which reduces wasting disk I/O for row-based stores: multiple queries attached to the same scan will typically access most columns (collectively). We are also vertically partitioning our widest table into frequently-accessed and infrequently-accessed columns to get some of the advantage of a column store.
Nevertheless, a column store could still be more efficient. Work done at Google (using Dremel) has claimed that “the crossover point often lies at dozens of fields but it varies across data sets” [22]. In our case, the most frequently accessed table: Object, will have over “20 dozens” columns. The Source, DiaObject, and DiaSource tables will each have about 4 dozen columns. These could be wide enough that all simultaneously executing queries will still only touch a subset of the columns. Most other large tables are relatively narrow and are expected to have all columns used by every query. Low query selectivity (expected to be <1% for full table scans) combined with late materialization (postponing row assembly until the last possible moment) is expected to further boost effectiveness of columnar stores.
The two leading row-based DBMSes are MySQL and PostgreSQL. Of these two, MySQL is better supported, and has much wider community of users, although both are commercially supported (MySQL: Oracle, MontyProgram+SkySQL, Percona. PostgreSQL: EnterpriseDB). PostgreSQL tends to focus more on OLTP, while MySQL is closer to our analytical needs, although both are weak in the area of scalability. One of the strongest points of PostgreSQL used to be spatial GIS support, however MySQL has recently rewritten their GIS modules and it now offers true spatial relationship support (starting from version 5.6.1). Neither provides good support for spherical geometry including wraparound, however.
Many commercial row-bases DBMSes exist, including Oracle, SQL Server, DB2, but they do not fit well into LSST needs, since we would like to provide all scientists with the ability to install the LSST database at their institution at low licensing and maintenance cost.
Columnar stores are starting to gain in popularity. Although the list is already relatively large, the number of choices worth considering is relatively small. Today’s most popular commercial choice is HP Vertica, and the open source solutions include MonetDB [20] [17] and Calpont’s InfiniDB. The latter also implements shared nothing MPP, however the multi-server version is only available as part of the commercial edition.
With help from Calpont, we evaluated InfiniDB and demonstrated it could be used for the LSST system – we run the most complex (near neighbor) query. Details are available in [36].
We are working closely with the MonetDB team, including the main architect of the system, Martin Kersten and two of his students who worked on porting MonetDB to meet LOFAR database needs. In 2011 the MonetDB team has run some basic tests using astronomical data (USNOB as well as our DC3b-PT1.1 data set [21]). During the course of testing our common queries they implemented missing features such as support for user defined functions, and are actively working on further extending MonetDB to build remaining missing functionality, in particular ability to run as a shared-nothing system. To achieve that, existing MonetDB server (merovingian) has to be extended. Table partitioning and overlaps (on a single node) can be achieved through table views, although scalability to LSST sizes still needs to be tested. Cross-node partitioning requires new techniques, and the MonetDB team is actively working on it.
In 2012 with help from the MonetDB team we demonstrated a limited set of queries on a Qserv system integrated with MonetDB on the backend rather than MySQL.[*] While the integration was left incomplete, the speed at which we were able to port Qserv to a new database and execute some queries is convincing evidence of Qserv’s modularity. Because basic functionality was ported in one week, we are confident that porting to another DBMS can be done with modest effort in a contingency or for other reasons. The experience has also guided Qserv design directions and uncovered unintended MySQL API dependence in Qserv and broader LSST DM systems.
1.4.4 Appliances¶
Appliances rely on specialized hardware to achieve performance. In general, we are skeptical about appliances, primarily because they are locking us into this specialized hardware. In addition, appliances are usually fast, however their replacement cost is high, so often commodity hardware is able to catch up, or even exceed the performance of an appliance after few years (the upgrade of an appliance to a latest version is usually very costly).
1.5 Comparison and Discussion¶
The MR processing paradigm became extremely popular in the last few years, in particular among peta-scale industrial users. Most industrial users with peta-scale data sets heavily rely on it, including places such as Google, Yahoo!, Amazon or Facebook, and even eBay has recently started using Hadoop for some of their (offline, batch) analysis. The largest (peta-scale) RDBMS-based systems all rely on shared-nothing, MPP technology, and almost all on expensive Teradata solutions (eBay, Walmart, Nokia, for a few years eBay used Greenplum but they switched back to Teradata’s Singularity).
In contrast, science widely adopted neither RDBMS nor MR. The community with the largest data set, HEP, is relying on a home-grown system, augmented by a DBMS (typically Oracle or MySQL) for managing the metadata. This is true for most HEP experiments of the last decade (with the exception of BaBar which initially used Objectivity), as well as the LHC experiments. In astronomy, most existing systems as well as the systems starting in the near future are RDBMS-based (SDSS – SQL Server, Pan-STARRS – SQL Server, 2MASS – Informix, DES – Oracle, LOFAR – MonetDB, Gaia – Caché). It is worth noting that none of these systems was large enough so far to break the single-node barrier, with the exception of Pan-STARRS. Geoscience relies primarily on netCDF/HDF5 files with metadata in a DBMS. Similar approach is taken by bio communities we have talked to. In general, MR approach has not been popular among scientific users so far.
The next few sections outline key differences, strengths and weaknesses of MR and RDBMS, and the convergence.
1.5.1 APIs¶
In the MR world, data is accessed by a pair of functions, one that is “mapped” to all inputs, and one that “reduces” the results from the parallel invocations of the first. Problems can be broken down into a sequence of MR stages whose parallel components are explicit. In contrast, a DBMS forces programmers into less natural, declarative thinking, giving them very little control over the flow of the query execution; this issue might partly go away by interacting with database through a user defined function (UDFs), which are becoming increasingly popular. They must trust the query optimizer’s prowess in “magically” transforming the query into a query plan. Compounding the difficulty is the optimizer’s unpredictability: even one small change to a query can make its execution plan efficient or painfully slow.
The simplicity of the MR approach has both advantages and disadvantages. Often a DBMS is able to perform required processing on the data in a small number of passes (full table scans). The limited MR operators on the other hand may lead to many more passes through the data, which requires more disk I/O thus reduces performance and increases hardware needed. Also, MR forced users to code a lot of operations typically provided by an RDBMS by-hand – these include joins, custom indexes or even schemas.
1.5.2 Scalability, fault tolerance and performance¶
The simple processing framework of MR allows to easily, incrementally scale the system out by adding more nodes as needed. Frequent check-pointing done by MR (after every “map” and every “reduce” step) simplifies recoverability, at the expense of performance. In contrast, databases are built with the optimistic assumptions that failures are rare: they generally checkpoint only when necessary. This has been shown through various studies [27].
The frequent checkpointing employed by MR, in combination with limited set of operators discussed earlier often leads to inefficient usages of resources in MR based systems. Again, this has been shown through various studies. EBay’s case seems to support this as well: back in 2009 when they managed 6.5 petabytes of production data in an RDBMS-based system they relied on a mere 96 nodes, and based on discussions with the original architects of the eBay system, to achieve comparable processing power through MR, many thousand nodes would be required.
1.5.3 Flexibility¶
MR paradigm treats a data set as a set of key-value pairs. It is structure-agnostic, leaving interpretation to user code and thus handling both poorly-structured and highly-complex data. Loose constraints on data allow users to get to data quicker, bypassing schema modeling, complicated performance tuning, and database administrators. In contrast, data in databases are structured strictly in records according to well-defined schemata.
While adjusting schema with ease is very appealing, in large scientific projects like LSST, the schema has to be carefully thought through to meet the needs of many scientific collaborations, each having a different set of requirements. The flexibility would be helpful during designing/debugging, however it is of lesser value for a science archive, compared to industry with rapidly changing requirements, and a strong focus on agility.
1.5.4 Cost¶
As of now, the most popular MR framework, Hadoop, is freely available as open source. In contrast, none of the freely available RDBMSes implements a shared-nothing MPP DBMS (to date), with the exception of SciDB, which can be considered only partially relational.
From the LSST perspective, plain MR does not meet project’s need, in particular the low-volume query short response time needs. Significant effort would be required to alleviate Hadoop’s high latency (today’s solution is to run idle MR daemons, and attach jobs to them, which pushes the complexity of starting/stopping jobs onto user code). Also, table joins, typically done in reduce stage, would have to be implemented as maps to avoid bringing data for joined tables to Reducer – in practice this would require implementing a clever data partitioning scheme. The main advantages of using MR as a base technology for the LSST system include scalability and fault-tolerance, although as alluded above, these features come at a high price: inefficient use of resources (full checkpointing between each Map and each Reduce step), and triple redundancy.
1.5.5 Summary¶
The key features of an ideal system, along with the comments for both Map/Reduce and RDBMS are given in the table below.
| Feature | Map/Reduce | RDBMS |
|---|---|---|
| Shared nothing, MPP, columnar | Implements it. | Some implement it, but only as commercial, non open source to date, except not-yet-mature SciDB. |
| Overlapping partitions, needed primarily for near-neighbor queries | Nobody implements this. | Only SciDB implements this to-date. |
| Shared scans (primarily for complex queries that crunch through large sets of data) | This kind of logic would have to be implemented by us. | There is a lot of research about shared scans in databases. Implemented by Teradata. Some vendors, including SciDB are considering implementing it |
| Efficient use of resources Catalog/schema | Very inefficient. Started adding support, e.g., Hive, HadoopDB |
Much better than MR. Much better than in MR. |
| Indexes (primarily for simple queries from public that require real time response) | Started adding support, e.g., Hive, HadoopDB | Much better than in MR. |
| Open source | Hadoop (although it is implemented in Java, not ideal from LSST point of view) | No shared-nothing MPP available as open source yet except still-immature SciDB. We expect there will be several by the time LSST needs it (SciDB, MonetDB, ParAccel and others) |
1.5.6 Convergence¶
Despite their differences, the database and MR communities are learning from each other and seem to be converging.
The MR community has recognized that their system lacks built-in operators. Although nearly anything can be implemented in successive MR stages, there may be more efficient methods, and those methods do not need to be reinvented constantly. MR developers have also explored the addition of indexes, schemas, and other database-ish features.[2] Some have even built a complete relational database system[3] on top of MR.
| [2] | An example of that is Hive. |
| [3] | An example of that is HadoopDB |
The database community has benefited from MR’s experience in two ways:
- Every parallel shared-nothing DBMS can use the MR execution style for internal processing – while often including more-efficient execution plans for certain types of queries. Though systems such as Teradata or IBM’s DB2 Parallel Edition have long supported this, a number of other vendors are building new shared-nothing-type systems.[4] It is worth noting that these databases typically use MR-style execution for aggregation queries.
- Databases such as Greenplum (part of EMC) and Aster Data (part of Teradata since March 2011) have begun to explicitly support the MR programming model with user-defined functions. DBMS experts have noted that supplying the MR programming model on top of an existing parallel flow engine is easy, but developing an efficient parallel flow engine is very hard. Hence it is easier for the DMBS community to build map/reduce than for the map/reduce community to add full DBMS functionality.
| [4] | ParAccel, Vertica, Aster Data, Greenplum, DATAllegro (now part of Microsoft), Datapuia, Exasol and SciDB |
The fact MR community is rapidly adding database/SQL like features on top of their plain MR (Tenzing, Hive, HadoopDB, etc), confirms the need for database-like features (indexes, schemas, catalogs, sql).
As we continue monitoring the latest development in both RDBMS and MR communities and run more tests, we expect to re-evaluate our choices as new options become available.
2 Map/Reduce Solutions¶
2.1 Hadoop¶
Hadoop is a Lucene sub-project hosted by Apache. It is open source. It tries to re-create the Google MR technology [10] to provide a framework in which parallel searches/projections/transformations (the Map phase) and aggregations/groupings/sorts/joins (the Reduce phase) using key-value pairs can be reliably performed over extremely large amounts of data. The framework is written in Java though the actual tasks executing the map and reduce phases can be written in any language as these are scheduled external jobs. The framework is currently supported for GNU/Linux platforms though there is on-going work for Windows support. It requires that ssh be uniformly available in order to provide daemon control.
Hadoop consists of over 550 Java classes implementing multiple components used in the framework:
- The Hadoop Distributed File System (HDFS), a custom POSIX-like file system that is geared for a write-once-read-many access model. HDFS is used to distribute blocks of a file, optionally replicated, across multiple nodes. HDFS is implemented with a single Namenode that maintains all of the meta-data (i.e., file paths, block maps, etc.) managed by one or more Datanodes (i.e., a data server running on each compute node). The Namenode is responsible for all meta-data operations (e.g., renames and deletes) as well as file allocations. It uses a rather complicated distribution algorithm to maximize the probability that all of the data is available should hardware failures occur. In general, HDFS always tries to satisfy read requests with data blocks that are closest to the reader. To that extent, HDFS also provides mechanisms, used by the framework, to co-locate jobs and data. The HDFS file space is layered on top of any existing native file system.
- A single JobTracker, essentially a job scheduler responsible for submitting and tracking map/reduce jobs across all of the nodes.
- A TaskTracker co-located with each HDFS DataNode daemon which is responsible for actually running a job on a node and reporting its status.
- DistributedCache to distribute program images as well as other required read-only files to all nodes that will run a map/reduce program.
- A client API consisting of JobConf, JobClient, Partitioner, OutputCollector, Reporter, InputFormat, OutputFormat among others that is used to submit and run map/reduce jobs and retrieve the output.
Hadoop is optimized for applications that perform a streaming search over large amounts of data. By splitting the search across multiple nodes, co-locating each with the relevant data, wherever possible, and executing all the sub-tasks in parallel, results can be obtained (relatively) quickly. However, such co-ordination comes with a price. Job setup is a rather lengthy process and the authors recommend that the map phase take at least a minute to execute to prevent job-setup from dominating the process. Since all of the output is scattered across many nodes, the map phase must also be careful to not produce so much output as to overwhelm the network during the reduce phase, though the framework provides controls for load balancing this operation and has a library of generally useful mappers and reducers to simplify the task. Even so, running ad hoc map/reduce jobs can be problematic. The latest workaround used by many Hadoop users involves running Hadoop services continuously (and jobs are attached to these services very fast). By default, joining tables in MR involves transferring data for all the joined tables into the reducer, and performing the join in the reduce stage, which can easily overwhelm the network. To avoid this, data must be partitioned, and data chunked joined together must be placed together (on the same node), in order to allow performing the join in the map stage.
Today’s implementation of Hadoop requires full data scan even for simplest queries. To avoid this, indices are needed. Implementing indices has been planned by the community for several years, and according to the latest estimates they will be implemented in one or two years. In the meantime, those who need indices must implement and maintain them themselves, the index files can be stored e.g. as files in the Hadoop File System (HDFS).
One of the “features” of MR systems is lack of official catalog (schema); instead, knowledge about schema in part of the code. While this dramatically improves flexibility and speeds up prototyping, it makes it harder to manage such data store in the long term, in particular if multi-decade projects with large number of developers are involved.
Lack of some features that are at the core of every database system should not be a surprise – MR systems are simply built with different needs in mind, and even the Hadoop website officially states that *Hadoop is not a substitute for a database*. Nethertheless, many have attempted to compare Hadoop performance with databases. According to some publications and feedback from Hadoop users we talked to, Hadoop is about an order of magnitude more wasteful of hardware than a e.g. DB2 [12] [11].
Hadoop has a large community supporting it; e.g., over 300 people attended the first Hadoop summit (in 2008). It is used in production by many organizations, including Facebook, Yahoo!, and Amazon Facebook. It is also commercially supported by Cloudera. Hadoop Summit 2011 was attended by more than 1,600 people from more than 400 companies.
We evaluated Hadoop in 2008. The evaluation included discussions with key developers, including Eric Baldeschwieler from Yahoo!, Jeff Hammerbacher from Facebook, and later Cloudera, discussions with users present at the 1st Hadoop Summit, and a meeting with the Cloudera team in September of 2010.
2.2 Hive¶
Hive is a data warehouse infrastructure developed by Facebook on top of Hadoop; it puts structures on the data, and defines SQL-like query language. It inherits Hadoop’s deficiencies including high latency and expensive joins. Hive works on static data, it particular it can’t deal with changing data, as row-level updates are not supported. Although it does support some database features, it is a “state where databases were ~1980: there are almost no optimizations” (based on Cloudera, meeting at SLAC Sept 2010). Typical solutions involve implementing missing pieces in user code, for example once can build their own indexes and interact directly with HDFS (and skip the Hadoop layer).
2.3 HBase¶
HBase is a column-oriented structured storage modeled after Google’s Bigtable [7], and built on top of the Hadoop HDFS. It is good at incremental updates and column key lookups, however, similarly to plain MR, it offers no mechanism to do joins – a typical solution used by most users is to denormalize data. HBase is becoming increasingly more popular at Facebook [28]. It is supported commercially by Cloudera, Datameer and Hadapt.
2.4 Pig Latin¶
Pig Latin is a procedural data flow language for expressing data analysis programs. It provides many useful primitives including filter, foreach ... generate, group, join, cogroup, union, sort and distinct, which greatly simplify writing Map/Reduce programs or gluing multiple Map/Reduce programs together. It is targeted at large-scale summarization of datasets that typically require full table scans, not fast lookups of small numbers of rows. We have talked to the key developer of Pig Latin – Chris Olston.
2.6 Dryad¶
Dryad [19] is a system developed by Microsoft Research for executing distributed computations. It supports a more general computation model than MR in that it can execute graphs of operations, using so called Directed Acyclic Graph (DAG). It is somewhat analogous to the MR model in that it can model MR itself, among others, more complex flows. The graphs are similar to the query plans in a relational database. The graph execution is optimized to take advantage of data locality if possible, with computation moving to the data. If non-local data is needed, it is transferred over the network.
Dryad currently works on flat files. It is similar to Hadoop in this way.
The core execution engine in Dryad has been used in production for several years but not heavily. There are several integration pieces we might want (loading data from databases instead of files, tracking replicas of data) that do not yet exist.
Beyond the execution engine, Dryad also incorporates a simple per-node task scheduler inherited from elsewhere in Microsoft. It runs prioritized jobs from a queue. Dryad places tasks on nodes based on the data available on the node and the state of the task queue on the node. A centralized scheduler might improve things, particularly when multiple simultaneous jobs are running; that is an area that is being investigated.
Dryad requires that the localization or partitioning of data be exposed to it. It uses a relatively generic interface to obtain this metadata from an underlying filesystem, enabling it to talk to either a proprietary GFS-like filesystem or local disks.
Dryad runs only on Windows .NET at present. Building the system outside of Microsoft is difficult because of dependencies on internal libraries; this situation is similar to the one with Google’s GFS and Map/Reduce. The core execution engine could conceivably be implemented within Hadoop or another system, as its logic is not supposed to be terribly complicated. The performance-critical aspect of the system is the transfer of data between nodes, a task that Windows and Unix filesystems have not been optimized for and which Dryad therefore provides.
Dryad has been released as open source to academics/researchers in July 2009. This release however does not include any distributed filesystem for use with the system. Internally, Microsoft uses the Cosmos file system, but it is not available in the academic release. Instead there are bindings for NTFS and SQL Server.
2.7 Dremel¶
Dremel is a scalable, interactive ad-hoc query system for analysis of read-only data, implemented as an internal project at Google [22]. Information about Dremel has been made available in July 2010. Dremel’s architecture is in many ways similar to our baseline architecture (executing query in parallel on many nodes in shared nothing architecture, auto fail over, replicating hot spots). Having said that, we do not have access to the source code, even though Google is an LSST collaborator, and there is no corresponding open source alternative to date.
2.8 Tenzing¶
Tenzing is an SQL implementation on the MapReduce Framework [8] We managed to obtain access to pre-published paper from Google through our XLDB channels several months before planned publication at the VLDB 2011 conference.
Tenzing is a query engine built on top of MR for ad hoc analysis of Google data. It supports a mostly complete SQL implementation (with several extensions) combined with several key characteristics such as heterogeneity, high performance, scalability, reliability, metadata awareness, low latency support for columnar storage and structured data, and easy extensibility.
The Tenzing project underscores importance and need of database-like features in any large scale system.
2.9 “NoSQL”¶
The popular term NoSQL originally refered to systems that do not expose SQL interface to the user, and it recently evolved and refers to structured systems such as key-value stores or document stores. These systems tend to provide high availability at the cost of relaxed consistency (“eventual” consistency). Today’s key players include Cassandra and MongoDB.
While a key/value store might come handy in several places in LSST, these systems do not address many key needs of the project. Still, a scalable distributed key-value store may be appropriate to integrate as an indexing solution within a larger solution.
3 Database Solutions¶
In alphabetical order.
3.1 Actian¶
Actian, formerly known as Ingres provides analytical services through Vectorwise, acquired from CWI in 2010. Primary speed ups rely on exploiting data level parallelism (rather than tuple-at-a-time processing). Main disadvantage from LSST perspective: it is a single-node system.
3.2 Caché¶
InterSystems Caché is a shared-nothing object database system, released as an embedded engine since 1972. Internally it stores data as multi-dimensional arrays, and interestingly, supports overlaps. We are in discussions with the company—we have been discussing Caché with Stephen Angevine since early 2007, and met with Steven McGlothlin in June 2011. We also discussed Caché with William O’Mullane from the ESA’s Gaia mission [40], an astronomical survey that selected Caché as their underlying database store in 2010 [39]). InterSystems offers free licensing for all development and research, for academic and non-profit research, plus support contracts with competitive pricing. However, their system does not support compression and stores data in strings, which may not be efficient for LSST catalog data.
A large fraction of the code is already available as open source for academia and non-profit organizations under the name “Globals” [18].
3.3 CitusDB¶
CitusDB is a new commercial distributed database built on top on PostgreSQL. It supports joins between one large and multiple small tables (star schema) – this is insufficient for LSST.
3.4 DB2¶
IBM’s DB2 “parallel edition” implements a shared-nothing architecture since mid-1990. Based on discussions with IBM representatives including Guy Lohman (e.g., at the meeting in June 2007) as well as based on various news, it appears that IBM’s main focus is on supporting unstructured data (XML), not large scale analytics. All their majors projects announced in the last few years seem to confirm them, including Viper, Viper2 and Cobra (XML) and pureScale (OLTP).
3.5 Drizzle¶
Drizzle is a fork from the MySQL Database, the fork was done shortly after the announcement of the acquisition of MySQL by Oracle (April 2008). Drizzle is lighter than MySQL: most advanced features such as partitioning, triggers and many others have been removed (the code base was trimmed from over a million lines down to some 300K, it has also been well modularized). Drizzle‘s main focus is on the cloud market. It runs on a single server, and there are no plans to implement shared-nothing architecture. To achieve shared-nothing architecture, Drizzle has hooks for an opaque sharding key to be passed through client, proxy, server, and storage layers, but this feature is still under development, and might be limited to hash-based sharding.
Default engine is InnoDB. MyISAM engine is not part of Drizzle, it is likely MariaDB engine will become a replacement for MyISAM.
Drizzle’s first GA release occurred in March 2011.
We have discussed the details of Drizzle with key Drizzle architects and developers, including Brian Aker (the chief architect), and most developers and users present at the Drizzle developers meeting in April 2008.
Note
In 2017 Drizzle is no longer being developed: https://en.wikipedia.org/wiki/Drizzle_(database_server) and the Drizzle web site no longer operates.
3.6 Greenplum¶
Greenplum is a commercial parallelization extension of PostgreSQL. It utilizes a shared-nothing, MPP architecture. A single Greenplum database image consists of an array of individual databases which can run on different commodity machines. It uses a single Master as an entry point. Failover is possible through mirroring database segments. According to some, it works well with simple queries but has issues with more complex queries. Things to watch out for: distributed transaction manager, allegedly there are some issues with it.
Up until recently, Greenplum powered one of the largest (if not the largest) database setups: eBay was using it to manage 6.5 petabytes of data on a 96-node cluster [24]. We are in close contact with the key eBay developers of this system, including Oliver Ratzesberger.
We are in contact with the Greenplum CTO: Luke Lonergan.
08/28/2008: Greenplum announced supporting MapReduce [38].
Acquired by EMC in July 2010.
3.7 GridSQL¶
GridSQL is an open source project sponsored by EnterpriseDB. GridSQL is a thin layer written on top of postgres that implemented shared-nothing clustered database system targeted at data warehousing. This system initially looked very promising, so we evaluated it in more details, including installing it on our 3-node cluster and testing its capabilities. We determined that currently in GridSQL, the only way to distribute a table across multiple nodes is via hash partitioning. We can’t simply hash partition individual objects, as this would totally destroy data locality, which is essential for spatial joins. A reasonable workaround is to hash partition entire declination zones (hash partition on zoneId), this will insure all objects for a particular zone end up on the same node. Further, we can “chunk” each zone into smaller pieces by using a regular postgres range partitioning (sub-tables) on each node.
The main unsolved problems are:
- near neighbor queries. Even though it is possible to slice a large table into pieces and distribute across multiple nodes, it is not possible to optimize a near neighbor query by taking advantage of data locality – GridSQL will still need to do n2 correlations to complete the query. In practice a special layer on top of GridSQL is still needed to optimize near neighbor queries.
- shared scans.
Another issue is stability, and lack of good documentation.
Also since GridSQL is based on PostgreSQL, it inherits the postgres “cons”, such as the slow performance (comparing to MySQL) and having to reload all data every year.
The above reasons greatly reduce the attractiveness of GridSQL.
We have discussed in details the GridSQL architecture with their key developer, Mason Sharp, who confirmed the issues we identified are unlikely to be fixed/implemented any time soon.
3.7.1 Gridsql Tests¶
We installed GridSQL on a 3 node cluster at SLAC and run tests aimed to uncover potential bottlenecks, scalability issues and understand performance. For these tests we used simulated data generated by the software built for LSST by the UW team.
Note that GridSQL uses PostgreSQL underneath, so these tests included installing and testing PostgreSQL as well.
For these tests we used the USNO-B catalog. We run a set of representative queries, ranging from low volume queries (selecting a single row for a large catalog, a cone search), to high-volume queries (such as near-neighbor search).
Our timing tests showed acceptable overheads in performance compared to PostgreSQL standalone.
We examined all data partitioning options available in GridSQL. After reading documentation, interacting with GridSQL developers, we determined that currently in GridSQL, the only way to distribute a table across multiple nodes is via hash partitioning. We can’t simply hash partition individual objects, as this would totally destroy data locality, which is essential for spatial joins. A reasonable workaround we found is to hash partition entire declination zones (hash partition on zoneId), this will insure all objects for a particular zone end up on the same node. Further, we can “chunk” each zone into smaller pieces by using a regular PostgreSQL range partitioning (sub-tables) on each node.
We were unable to find a clean solution for the near neighbor queries. Even though it is possible to slice a large table into pieces and distribute across multiple nodes, it is not possible to optimize a near neighbor query by taking advantage of data locality, so in practice GridSQL will still need to do n2 correlations to complete the query. In practice a special layer on top of GridSQL is still needed to optimize near neighbor queries. So in practice, we are not gaining much (if anything) by introducing GridSQL into our architecture.
During the tests we uncovered various stability issues, and lack of good documentation.
In addition, GridSQL is based on PostgreSQL, so it inherits the PostgreSQL “cons”, such as the slow performance (comparing to MySQL) and having to reload all data every year, described separately.
3.8 InfiniDB¶
InfiniDB is an open source, columnar DBMS consisting of a MySQL front end and a columnar storage engine, build and supported by Calpont. Calpont introduced their system at the MySQL 2008 User Conference [35], and more officially announced it in late Oct 2009. It implements true MPP, shared nothing (or shared-all, depending how it is configured) DBMS. It allows data to be range-based horizontal partitioning, partitions can be distributed across many nodes (overlapping partitions are not supported though). It allows to run distributed scans, filter aggregations and hash joins, and offers both intra- and inter- server parallelism. During cross-server joins: no direct communication is needed between workers. Instead, they build 2 separate hash maps, distribute smaller one, or if too expensive to distribute they can put it on the “user” node.
A single-server version of InfiniDB software is available through free community edition. Multi-node, MPP version of InfiniDB is only available through commercial, non-free edition, and is closed source.
We are in contact with Jim Tommaney, CTO of the Calpont Corporation since April 2008. In late 2010 we run the most demanding query – the near neighbor tests using Calpont. Details of these tests are covered in [36].
3.9 LucidDB¶
LucidDB is an open source columnar DBMS. Early startup (version 0.8 as of March 2009). They have no plans to do shared-nothing (at least there is no mention of it, and on their main page they mention “great performance using only a single off-the-shelf Linux or Windows server.”). Written mostly in java.
3.10 MySQL¶
MySQL utilizes a shared-memory architecture. It is attractive primarily because it is a well supported, open source database with a large company (now Oracle) behind it and a big community supporting it. (Note, however, that much of that community uses it for OLTP purposes that differ from LSST’s needs.) MySQL’s optimizer used be below-average, however it is slowly catching up, especially the MariaDB version.
We have run many, many performance tests with MySQL. These are documented in [3].
We are well plugged into the MySQL community, we attended all MySQL User Conferences in the past 5 years, and talked to many MySQL developers, including director of architecture (Brian Aker), the founders (Monty Widenius, David Axmark), and theMySQL optimizer gurus.
There are several notable open-source forks of MySQL:
- The main one, supported by Oracle. After initial period when Oracle was pushing most new functionality into commercial version of MySQL only [Error: Reference source not found], the company now appears fully committed to support MySQL, arguing MySQL is a critical component of web companies and it is one of the components of the full stack of products they offer. Oracle has doubled the number of MySQL engineers and tripled the number of MySQL QA staff over the past year [37], and the community seems to believe Oracle is truly committed now to support MySQL. The main “problem” from LSST perspective is that Oracle is putting all the effort into InnoDB engine only (the engine used by web companies including Facebook and Google), while the MyISAM engine, the engine of choice for LSST, selected because of vastly different access pattern characteristics, remains neglected and Oracle currently has no plans to change that.
- MontyProgram and SkySQL used to support two separate forks of MySQL, in April 2013 they joint efforts; the two founders of MySQL stand behind these two companies. MontyProgram is supporting a viable alternative to InnoDB, called MariaDB, and puts lots of efforts into improving and optimizing MyISAM. As an example, the mutli-core performance issues present in all MySQL engines in the past were fixed by Oracle for InnoDB, and in Aria, the MontyProgram’s version of MyISAM by MontyProgram.
- Percona, which focuses on multi-core scaling
- Drizzle, which is a slimmed-down version, rewriten from scratch and no longer compatible with MySQL. Based on discussions with the users, the Drizzle effort has not picked up, and is slowly dying.
Spatial indexes / GIS. As of version 5.6.1, MySQL has rewritten spatial support, added support for spatial indexes (for MyISAM only) and functions using the OpenGIS geometry model. We have not yet tested this portion of MySQL, and have preferred using geometry functionality from SciSQL, a MySQL plug-in written inhouse..
3.10.1 MySQL – Columnar Engines¶
3.10.1.1 KickFire¶
KickFire is a hardware appliance built for MySQL. It runs a proprietary database kernel (a columnar data store with aggressive compression) with operations performed on a custom dataflow SQL chip. An individual box can handle up to a few terabytes of data. There are several factors that reduce the attractiveness of this approach:
- it is a proprietary “black box”, which makes it hard to debug, plus it locks us into a particular technology
- it is an appliance, and custom hardware tends to get obsolete fairly rapidly
- it can handle low numbers of terabytes; another level is still needed (on top?) to handle petabytes
- there is no apparent way to extend it (not open source, all-in-one “black box”)
We have been in contact with the key people since April of 2007, when the team gave us a demo of their appliance under an NDA.
3.10.1.2 InfoBright¶
Infobright is a proprietary columnar engine for MySQL. Infobright Community Edition is open-source, but lacks many features, like parallelism and DML (INSERT, UPDATE, DELETE, etc). Infobright Enterprise Edition is closed-source, but supports concurrent queries and DML. Infobright’s solution emphasizes single-node performance without discussing distributed operation (except for data ingestion in the enterprise edition).
3.10.2 TokuDB¶
Tokutek built a specialized engine, called TokuDB. The engine relies on new indexing method, called Fractal Tree indexes [34], this new type of an index primarily increases speed of inserts and data replication. While its benefits are not obvious for our data access center, rapid inserts might be useful for Level 1 data sets (Alert Production). We have been in touch with the Tokutek team for several years, the key designers of the Fractal Tree index gave a detailed tutorial at the XLDB-2012 conference we organized.
The engine was made open source in Apr 2013.
3.11 Netezza¶
Netezza Performance Server (NPS) is a proprietary, network attached, streaming data warehousing appliance that can run in a shared-nothing environment. It is built on PostgreSQL.
The architecture of NPS consists of two tiers: a SMP host and hundreds of massively parallel blades, called Snippet Processing Units (SPU). Each SPU consists of a CPU, memory, disk drive and an FPGA chip that filters records as they stream off the disk. See https://www-01.ibm.com/software/data/netezza/ for more information.
According to some rumours, see e.g. [23], Netezza is planning to support map/reduce.
Pros:
- It is a good, scalable solution
- It has good price/performance ratio.
Cons:
- it is an appliance, and custom hardware tends to get obsolete fairly rapidly
- high hardware cost
- proprietary
Purchased by IBM.
3.12 Oracle¶
Oracle provides scalability through Oracle Real Application Clusters (RAC). It implements a shared-storage architecture.
Cons: proprietary, expensive. It ties users into specialized (expensive) hardware (Oracle Clusterware) in the form of storage area networks to provide sufficient disk bandwidth to the cluster nodes; the cluster nodes themselves are often expensive shared-memory machines as well. It is very expensive to scale to very large data sets, partly due to the licensing model. Also, the software is very monolithic, it is therefore changing very, very slowly.
We have been approached several times by Oracle representatives, however given we believe Oracle is not a good fit for LSST, we decided not to invest our time in detailed investigation.
3.13 ParAccel¶
ParAccel Analytic Database is a proprietary RDBMS with a shared-nothing MPP architecture using columnar data storage. They are big on extensibility and are planning to support user-defined types, table functions, user-defined indexes, user-defined operators, user-defined compression algorithms, parallel stored procedures and more.
When we talked to ParAccel representatives (Rick Glick, in May 2008), the company was still in startup mode.
3.14 PostgreSQL¶
PostgreSQL is an open source RDBMS running in a shared-memory architecture.
PostgreSQL permits horizontal partitioning of tables. Some large-scale PostgreSQL-based applications use that feature to scale. It works well if cross-partition communication is not required.
The largest PostgreSQL setup we are aware of is AOL’s 300 TB installation (as of late 2007). Skype is planning to use PostgreSQL to scale up to billions of users, by introducing a layer of proxy servers which will hash SQL requests to an appropriate PostgreSQL database server, but this is an OLTP usage that supports immense volumes of small queries [16].
PostgreSQL also offers good GIS support [26]. We are collaborating with the main authors of this extension.
One of the main weaknesses of PostgreSQL is a less-developed support system. The companies that provide support contracts are less well-established than Sun/MySQL. Unlike MySQL, but more like Hadoop, the community is self-organized with no single central organization representing the whole community, defining the roadmap and providing long term support. Instead, mailing lists and multiple contributors (people and organizations) manage the software development.
PostgreSQL is more amenable to modification than MySQL, which may be one reason why it has been used as the basis for many other products, including several mentioned below.
Based on the tests we run, PostgreSQL performance is 3.7x worse than MySQL. We realize the difference is partly due to very different characteristics of the engines used in these tests (fully ACID-compliant PostgreSQL vs non-transactional MyISAM), however the non-transactional solution is perfectly fine, and actually preferred for our immutable data sets.
We are in touch with few most active PostgreSQL developers, including the authors of Q3C mentioned above, and Josh Berkus.
3.14.1 Tests¶
We have run various performance tests with PostgreSQL to compare its performance with MySQL. These tests are described in details in the “Baseline architecture related” section below. Based on these tests we determined PostgreSQL is significantly (3.7x) slower than MySQL for most common LSST queries.
We have also tried various partitioning schemes available in PostgreSQL. In that respect, we determined PostgreSQL is much more advanced than MySQL.
Also, during these tests we uncovered that PostgreSQL requires dump/reload of all tables for each major data release (once per year), see https://www.postgresql.org/support/versioning. The PostgreSQL community believes this is unlikely to change in the near future. This is probably the main show-stopper preventing us from adapting PostgreSQL.
3.15 SciDB¶
SciDB is a new open source system inspired by the needs of LSST15 and built for scientific analytics. SciDB implements a shared nothing, columnar MPP array database, user defined functions, overlapping partitions, and many other features important for LSST. SciDB Release 11.06, the first production release, was published on June 15, 2011. We are in the process of testing this release.
3.16 SQLServer¶
Microsoft’s SQLServer’s architecture is shared-memory. The largest SQLServer based setup we are aware of is the SDSS database (6 TB), and the Pan-STARRS database.
In 2008 Microsoft bought DATAllegro and began an effort, codenamed “Project Madison,” to integrate it into SQLServer. Madison relies on shared nothing computing. Control servers are connected to compute nodes via dual Infiniband links, and compute servers are connected to a large SAN via dual Fiber Channel links. Fault tolerance relies on (expensive) hardware redundancy. For example, servers tend to have dual power supplies. However, servers are unable to recover from storage node failures, thought a different replica may be used. The only way to distribute data across nodes is by hashing; the system relies on replicating dimension tables. [the above is based on the talk we attended [13]]
Cons: It is proprietary, relies on expensive hardware (appliance), and it ties users to the Microsoft OS.
About DATAllegro. DATAllegro was a company specializing in data warehousing server appliances that are pre-configured with a version of the Ingres database optimized to handle relatively large data sets (allegedly up to hundreds of terabytes). The optimizations reduce search space during joins by forcing hash joins. The appliances rely on high speed interconnect(Infiniband).
3.17 Sybase IQ¶
SybaseIQ (now SAP IQ) is a commercial columnar database product by Sybase Corp. SybaseIQ utilizes a “shared-everything” approach that designed to provide graceful load-balancing. We heard opinions that most of the good talent has left the company; thus it is unlikely it will be a major database player.
Cons: proprietary.
3.18 Teradata¶
Teradata implements a shared-nothing architecture. The two largest customers include eBay and WalMart. Ebay is managing multi petabyte Teradata-based database.
The main disadvantage of Teradata is very high cost.
We are in close contact with Steve Brobst, acting as Teradata CTO, and key database developers at eBay.
3.19 Vertica¶
The Vertica Analytics Platform is a commercial product based on the open source C-store column-oriented database, and now owned by HP. It utilizes a shared-nothing architecture. Its implementation is quite innovative, but involves signficant complexity underneath.
It is built for star/snowflake schemas. It currently can not join multiple fact tables; e.g. self-joins are not supported though this will be fixed in future releases. Star joins in the MPP environment are made possible by replicating dimension tables and partitioning the fact table.
In 2009, a Vertica Hadoop connector was implemented. This allows Hadoop developers to push down map operators to Vertica database, stream Reduce operations into Vertica, and move data between the two environments.
Cons:
- lack of support of self-joins
- proprietary..
3.20 Others¶
In addition to map/reduce and RDBMS systems, we also evaluation several other software packages which could be used as part of our custom software written on top of MySQL. The components needed include SQL parser, cluster management and task management.
3.20.1 Cluster and task and management¶
Two primary candidates to use as cluster and task management we identified so far are Gearman and XRootD. Cluster management involves keeping track of available nodes, allowing nodes to be added/removed dynamically. Task management involves executing tasks on the nodes.
Detailed requirements what we need are captured at: https://dev.lsstcorp.org/trac/wiki/db/Qserv/DistributedFrameworkRequirements
3.20.1.1 Gearman¶
Gearman is a distributed job execution system, available as open source. It provides task management functions, e.g., cluster management is left out to be handled in application code.
During a meeting setup in June 2009 with Eric Day, the key developer working on integration of Drizzle with Gearman, who also wrote the C++ version of Gearman, we discussed details of Gearman architecture and its applicability for LSST.
Gearman manages workers as resources that provide RPC execution capabilities. It is designed to provide scalable access to many resources that can provide similar functionality (e.g., compress an image, retrieve a file, perform some expensive computation). While we could imagine a scheme to use Gearman’s dispatch system, its design did not match LSST’s needs well. One problem was its store-and-forward approach to arguments and results, which would mean that the query service would need to implement its own side transmission channel or potentially flood the Gearman coordinator with bulky results.
4 Experiments on Hive¶
This section[†] discusses an evaluation of the Hive data warehouse infrastructure for LSST database needs. All experimentation and analysis done by Bipin Suresh in mid-2010.
4.1 Background¶
Hive is a data warehouse built upon Hadoop. It defines a SQL-like query language called QL which allows for queries on structured data. Since it is built on top of Hadoop, developers can leverage the Map-Reduce framework to define and perform more complicated analysis by plugging in their own custom mappers and reducers.
To get Hive running, you need to first have a working version of Hadoop.
4.2 Test Conditions¶
4.2.1 Software configuration¶
- Hive 0.7.0
- Hadoop 0.20.2
4.2.2 Schema¶
We have used a reduced Object schema based on USNO-B for testing purposes. For the final schema that we will be using, please check out the documentation here: http://ls.st/8g4
hive> desc object;
| id | int |
| ra | float |
| decl | float |
| pm_ra | int |
| pm_raerr | int |
| pm_decl | int |
| pm_declerr | int |
| epoch | float |
| bmag | float |
| bmagf | int |
| rmag | float |
| rmagf | int |
| bmag2 | float |
| bmagf2 | int |
| rmag2 | float |
| rmagf2 | int |
4.2.3 Test Queries¶
Analysis of a single object. Find an object with a particular objectId
hive> select * from object where id=1;
Select transient variable objects near a known galaxy
hive> select v.id, v.ra, v.decl from object v join object o where o.id=1 and spDist(v.ra, v.decl, o.ra, o.decl)<10;
Analysis of all objects meeting certain criteria
In a region select all galaxies in given area
hive> select * from object where areaSpec(ra, decl, 0, 0, 10, 10)=true;
For a specified patch of sky, give me the source count density of unresolved sources (star like PSF)
hive> select count(id) from object where areaSpec(ra, decl, 0, 0, 10, 10)=true;
Across entire sky. Random sample of the data
hive> select * from object tablesample(bucket 1 out of 1000 on rand());
Analysis of objects close to other objects. Find near-neighbor objects in a given region
hive> select o1.id, o2.id, spDist(o1.ra, o1.decl, o2.ra, o2.decl) from object o1 join object o2 where areaSpec(o1.ra, o1.decl, 0, 0, 10, 10)=true and spDist(o1.ra, o1.decl, o2.ra, o2.decl) < 5 and o1.id <> o2.id;
spdist function definition:
package com.example.hive.udf; import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.io.Text; public final class SpDist extends UDF { public double evaluate(final double ra1, final double dec1, final double ra2, final double dec2) { double dra, ddec, a, b, c; dra = radians(0.5 * (ra2 - ra1)); ddec = radians(0.5 * (dec2 - dec1)); a = Math.pow(Math.sin(ddec), 2) + Math.cos(radians(dec1)) * Math.cos(radians(dec2)) * Math.pow(Math.sin(dra), 2); b = Math.sqrt(a); c = b>1 ? 1 : b; return degrees(2.0 * Math.asin(c)); } private double radians(double a) { return Math.PI / 180 * a; } private double degrees(double a) { return a * 180 / Math.PI; } }areaspec function definition:
package com.example.hive.udf; import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.io.Text; public final class AreaSpec extends UDF { public boolean evaluate(double ra, double decl, final double raMin, final double declMin, final double raMax, final double declMax) { return (ra > raMin && ra < raMax && decl > declMin && decl < declMax); } }
Filtering by fields like variability and extendedParameter has been ignored for now since they are not available in the data. It should be trivial to add those conditions when the data is ready.
4.3 Performance¶
Hive is built on top of Hadoop, which is a framework for running applications across large clusters of commodity hardware. Hadoop/Hive handles data-distribution and aggregation reliably; and handles node-failures gracefully. Both data-movement and machine vagaries are transparent to the user/application-developer.
4.3.1 Single Node¶
Our first set of experiments were on a single machine, with a local copy of Hadoop running. The machine was a 64-bit Dual Core AMD Opteron, running at 1.8GHz, with 4GB of RAM.
On a single node, loading 715K worth of data (~10,000 records with 70bytes each) took 1.178secs. The execution time for each of the queries are listed below:
Q1:
select * from object where id=1;
Time taken: 11.88 seconds
Q2:
select v.id, v.ra, v.decl from object v join object o where o.id=1 and spDist(v.ra, v.decl, o.ra, o.decl)<10;
Time taken: 19.999 seconds
Q3:
select * from object where areaSpec(ra, decl, 0, 0, 10, 10)=true;
Time taken: 10.767 seconds
Q4:
select count(id) from object where areaSpec(ra, decl, 0, 0,10, 10)=true;
Time taken: 20.77 seconds
Q5:
select * from object tablesample(bucket 1 out of 1000 on rand());
Time taken: 11.665 seconds
Q6:
select o1.id, o2.id, spDist(o1.ra, o1.decl, o2.ra, o2.decl) from object o1 join object o2 where areaSpec(o1.ra, o1.decl, 0,0, 10, 10)=true and spDist(o1.ra, o1.decl, o2.ra, o2.decl) < 5 and o1.id <> o2.id;
Time taken: 23.053 seconds
4.3.2 Single Node w/Padded Data¶
To simulate the actual data we might be indexing, we padded the schema with a dummy field ‘pad’, which ensures that the size of each record >= 1k. The experiments below show the performance of the system with this dataset. The number of records were kept the same as the above experiments.
Load data time: 1.450s
Q1:
select * from object_padded where id=1;
Time taken: 12.66 seconds
Q2:
select v.id, v.ra, v.decl from object_padded v join object_padded o where o.id=1 and spDist(v.ra, v.decl, o.ra,o.decl)<10;
Time taken: 23.929 seconds
Q3:
select * from object_padded where areaSpec(ra, decl, 0, 0,10, 10)=true;
Time taken: 10.712 seconds
Q4:
select count(id) from object_padded where areaSpec(ra, decl,0, 0, 10, 10)=true;
Time taken: 21.81 seconds
Q5:
select * from object_padded tablesample(bucket 1 out of 1000 on rand());
Time taken: 10.684 seconds
Q6:
select o1.id, o2.id, spDist(o1.ra, o1.decl, o2.ra, o2.decl) from object_padded o1 join object_padded o2 where areaSpec(o1.ra, o1.decl, 0, 0, 10, 10)=true and spDist(o1.ra, o1.decl, o2.ra, o2.decl) < 5 and o1.id <> o2.id;
Time taken: 22.837 seconds
4.3.2.1 Padded Schema¶
hive> desc object_padded;
| id | int |
| ra | float |
| decl | float |
| pm_ra | int |
| pm_raerr | int |
| pm_decl | int |
| pm_declerr | int |
| epoch | float |
| bmag | float |
| bmagf | int |
| rmag | float |
| rmagf | int |
| bmag2 | float |
| bmagf2 | int |
| rmag2 | float |
| rmagf2 | int |
| pad | string |
4.3.3 3-node cluster¶
We set up a small 3-node cluster to study the performance of Hive across multiple machines. The machines were of the same class as the one used for the single-node experiment. The settings (number of mappers/reducers etc.) were not tweaked, allowing Hive to determine (guess?) the default parameters itself. The performance of the cluster is described below:
Load data time: 1.386s
Q1:
select * from object_padded where id=1;
Time taken: 15.888 seconds
Q2:
select v.id, v.ra, v.decl from object_padded v join object_padded o where o.id=1 and spDist(v.ra, v.decl, o.ra, o.decl)<10;
Time taken: 22.117 seconds
Q3:
select * from object_padded where areaSpec(ra, decl, 0, 0,10, 10)=true;
Time taken: 12.882 seconds
Q4:
select count(id) from object_padded where areaSpec(ra, decl, 0, 0, 10, 10)=true;
Time taken: 19.927 seconds
Q5:
select * from object_padded tablesample(bucket 1 out of 1000 on rand());
Time taken: 10.774 seconds
Q6:
select o1.id, o2.id, spDist(o1.ra, o1.decl, o2.ra, o2.decl)from object_padded o1 join object_padded o2 where areaSpec(o1.ra,o1.decl, 0, 0, 10, 10)=true and spDist(o1.ra, o1.decl, o2.ra, o2.decl) < 5 and o1.id <> o2.id;
Time taken: 19.996 seconds
At the small data size (10k rows), performance is about the same for 1-node and 3-node.
4.4 Larger scale testing¶
I setup and collected data for different Hive architectures. I tested:
- a single node setup
- an 8-node setup
- a 64-node setup.
4.4.1 Data setup¶
For every architecture, I loaded the 10M rows that Daniel Wang has generated, and ran the queries we had identified previously
The queries were restricted to queries on the Object table. No padding was used to increase the size of the rows to 1k.
For each architecture, I ran five runs of each query, and recorded the average running time. I’ve attached some analysis to this mail.
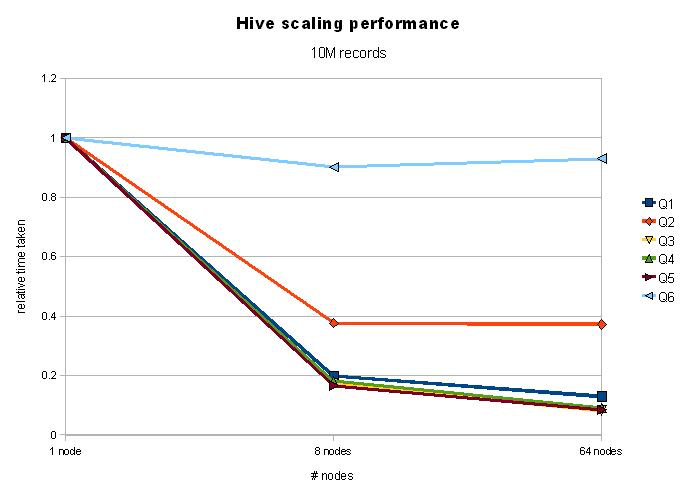
4.4.2 Conclusions¶
The main conclusions from these set of experiments are:
1. Hive scales well with increase in nodes. Increasing the number of nodes is a configuration change, followed by a restart. I suspect however, that data might have to re-partitioned/re-indexed if we add nodes dynamically.
2. Hive scales reasonably well with increase in data-size. A 1,000 fold increase in data-size (from 10,000 to 10,000,000 records) increased running times by ~30 times. More experiments will need to be done to pin that number down.
3. Adding more nodes improves performance: the query execution time typically drops by 50% when we move from a 1-node setup to an 8-node setup. Further increases in number of nodes decreases query-execution time still, but not as drastically. We’ll need to perform further experiments to tease out whether this is because of the (limited) data-size we’re using, or whether it’s because of the profile of the queries.
4. Query-6 stands apart in that it gains almost nothing by the inclusion of more nodes. Analysis shows that this is primarily because most of the time of this query is spent in the final Reduce step, which needs to aggregate the join, and results in a whopping 43k records. Further experiments will need to be done to identify the root of the bottleneck - whether it’s the large number of results, or whether it’s because of significant (single) reduce step.
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | |
|---|---|---|---|---|---|---|
| 1 node | ||||||
| Run 1 | 242.76 | 501.00 | 275.12 | 346.73 | 256.87 | 3868.26 |
| Run 2 | 243.79 | 509.66 | 278.76 | 337.29 | 302.32 | 3969.76 |
| Run 3 | 249.98 | 500.93 | 277.08 | 335.68 | 274.07 | 3828.15 |
| Run 4 | 249.54 | 498.00 | 284.76 | 342.79 | 245.70 | 4027.38 |
| Run 5 | 246.84 | 531.33 | 280.52 | 338.60 | 247.16 | 3629.87 |
| Average Execution time (sec) | 246.58 | 508.18 | 279.25 | 340.22 | 265.23 | 3864.68 |
| 8 nodes | ||||||
| Run 1 | 51.00 | 182.90 | 48.82 | 59.41 | 42.42 | 3470.91 |
| Run 2 | 49.48 | 197.72 | 49.52 | 62.57 | 44.96 | 3546.29 |
| Run 3 | 47.94 | 194.97 | 48.69 | 65.68 | 42.87 | 3438.10 |
| Run 4 | 47.78 | 199.85 | 47.58 | 59.53 | 44.12 | 3495.05 |
| Run 5 | 48.82 | 182.49 | 47.41 | 60.15 | 45.71 | 3482.68 |
| Average Execution time (sec) | 49.00 | 191.59 | 48.40 | 61.47 | 44.02 | 3486.61 |
| 64 nodes | ||||||
| Run 1 | 34.77 | 161.65 | 27.67 | 32.51 | 25.03 | 3499.31 |
| Run 2 | 29.19 | 195.06 | 21.98 | 31.36 | 22.96 | 3722.20 |
| Run 3 | 29.28 | 191.12 | 22.17 | 30.40 | 21.77 | 3582.00 |
| Run 4 | 34.48 | 201.16 | 20.80 | 33.37 | 20.90 | 3473.59 |
| Run 5 | 31.94 | 194.98 | 22.17 | 26.31 | 21.92 | 3700.11 |
| Average Execution time (sec) | 31.93 | 188.79 | 22.96 | 30.79 | 22.52 | 3595.44 |
Experimentation with Hive was done by Bipin Suresh
5 People/Communities We Talked To¶
Solution providers of considered products:
- Map/Reduce – key developers from Google
- Hadoop – key developers from Yahoo!, founders and key developers behind Cloudera and Hortonworks, companyies supporting enterprise edition of Hadoop
- Hive – key developers from Facebook.
- Dryad – key developers from Microsoft (Dryad is Microsofts’s version of map/reduce), including Michael Isard
- Gearman – key developers (gearman is a system which allows to run MySQL in a distributed fashion)
- representatives from all major database vendors, including Teradata, Oracle, IBM/DB2, Greenplum, Postgres, MySQL, MonetDB, SciDB
- representatives from promising startups including HadoopDB, ParAcell, EnterpriseDB, Calpont, Kickfire
- Intersystem’s Cache—Stephen Angevine, Steven McGlothlin
- Metamarkets
User communities:
- Web companies, including Google, Yahoo, eBay, AOL
- Social networks companies, including Facebook, LinkedIn, Twitter, Zynga and Quora
- Retail companies, including Amazon, eBay and Sears,
- Drug discovery (Novartis)
- Oil & gas companies (Chevron, Exxon)
- telecom (Nokia, Comcast, ATT)
- science users from HEP (LHC), astronomy (SDSS, Gaia, 2MASS, DES, Pan-STARRS, LOFAR), geoscience, biology
Leading database researchers
- M Stonebraker
- D DeWitt
- S Zdonik
- D Maier
- M Kersten
6 References¶
| [1] | J. Becla and K-T Lim. Report from the scidb workshop. Data Science Journal, September 2008. doi:10.2481/dsj.7.88. |
| [2] | [Document-8256]. Jacek Becla. Evaluation of Database Solutions. 2009. URL, https://ls.st/Document-8256. |
| [3] | [DMTN-048]. Jacek Becla, Kian-Tat Lim, and Daniel Wang. Qserv design prototyping experiments. 2011. LSST Data Management Technical Note. URL: https://dmtn-048.lsst.io |
| [4] | [LDM-135]. Jacek Becla, Daniel Wang, Serge Monkewitz, K-T Lim, Douglas Smith, and Bill Chickering. Database design. 2013. URL, https://ls.st/LDM-135. |
| [5] | Jacek Becla and Daniel L. Wang. Lessons learned from managing a petabyte. In CIDR 2005, Second Biennial Conference on Innovative Data Systems Research, Asilomar, CA, USA, January 4-7, 2005, Online Proceedings, 70–83. 2005. URL: http://cidrdb.org/cidr2005/papers/P06.pdf. |
| [6] | (1, 2) Mike Burrows. The chubby lock service for loosely-coupled distributed systems. In Proceedings of the 7th Symposium on Operating Systems Design and Implementation, OSDI ‘06, 335–350. Berkeley, CA, USA, 2006. USENIX Association. URL: http://dl.acm.org/citation.cfm?id=1298455.1298487. |
| [7] | (1, 2) Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber. Bigtable: a distributed storage system for structured data. ACM Trans. Comput. Syst., 26(2):4:1–4:26, June 2008. doi:10.1145/1365815.1365816. |
| [8] | (1, 2) B. Chattopadhyay, Liang Lin, Weiran Liu, Sagar Mittal P. Aragonda, V. Lychagina, Younghee Kwon, and Michael Wong. Tenzing a sql implementation on the mapreduce framework. In Proceedings of VLDB, volume 4, 1318–1327. 2011. URL: https://research.google.com/pubs/pub37200.html. |
| [9] | P. Cudre-Mauroux, H. Kimura, K.-T. Lim, J. Rogers, R. Simakov, E. Soroush, P. Velikhov, D. L. Wang, M. Balazinska, J. Becla, D. DeWitt, B. Heath, D. Maier, S. Madden, J. Patel, M. Stonebraker, and S. Zdonik. A demonstration of scidb: a science-oriented dbms. Proc. VLDB Endow., 2(2):1534–1537, August 2009. URL: http://dx.doi.org/10.14778/1687553.1687584, doi:10.14778/1687553.1687584. |
| [10] | (1, 2) Jeffrey Dean and Sanjay Ghemawat. Mapreduce: simplified data processing on large clusters. Commun. ACM, 51(1):107–113, January 2008. doi:10.1145/1327452.1327492. |
| [11] | David DeWitt. MapReduce II. January 2008. URL: https://web.archive.org/web/20090326224219/http://www.databasecolumn.com:80/2008/01/mapreduce-continued.html. |
| [12] | David DeWitt. MapReduce: A major step backwards. January 2008. URL: https://web.archive.org/web/20090327050223/http://www.databasecolumn.com/2008/01/mapreduce-a-major-step-back.html. |
| [13] | Paul Dyke. Microsoft SQL Server Project code-named ‘Madison’. PASS Summit Unite, 2009. URL: http://wiki.esi.ac.uk/w/files/5/5c/Dyke-Details_of_Project_Madison-1.pdf. |
| [14] | (1, 2) Mary Jo Foley. Microsoft drops Dryad; puts its big-data bets on Hadoop. November 2011. URL: http://www.zdnet.com/article/microsoft-drops-dryad-puts-its-big-data-bets-on-hadoop/. |
| [15] | Jim Gray. The zones algorithm for finding points-near-a-point or cross-matching spatial datasets. Technical Report MSR-TR-2006-52, Microsoft, April 2006. URL: https://www.microsoft.com/en-us/research/publication/the-zones-algorithm-for-finding-points-near-a-point-or-cross-matching-spatial-datasets/. |
| [16] | Todd Hoff. Skype Plans For PostgreSQL To Scale To 1 Billion Users. April 2008. URL: http://highscalability.com/skype-plans-postgresql-scale-1-billion-users. |
| [17] | Stratos Idreos, Fabian Groffen, Niels Nes, Stefan Manegold, K. Sjoerd Mullender, and Martin L. Kersten. Monetdb: two decades of research in column-oriented database architectures. IEEE Data Eng. Bull., 35(1):40–45, 2012. URL: http://sites.computer.org/debull/A12mar/monetdb.pdf. |
| [18] | Intersystems. Using Cache Globals. October 2008. URL: http://docs.intersystems.com/documentation/cache/20082/pdfs/GGBL.pdf. |
| [19] | Michael Isard, Mihai Budiu, Yuan Yu, Andrew Birrell, and Dennis Fetterly. Dryad: distributed data-parallel programs from sequential building blocks. In Proceedings of the 2Nd ACM SIGOPS/EuroSys European Conference on Computer Systems 2007, EuroSys ‘07, 59–72. New York, NY, USA, 2007. ACM. URL: http://doi.acm.org/10.1145/1272996.1273005, doi:10.1145/1272996.1273005. |
| [20] | M. Ivanova, N. Nes, R. Goncalves, and M. Kersten. MonetDB/SQL Meets SkyServer: the Challenges of a Scientific Database. In 19th International Conference on Scientific and Statistical Database Management (SSDBM 2007), 13. July 2007. doi:10.1109/SSDBM.2007.19. |
| [21] | [Document-9044]. Jeff Kantor, Tim Axelrod, Robyn Allsman, Mike Freemon, and K-T Lim. Data Challenge 3b Overview. 2010. URL, https://ls.st/Document-9044. |
| [22] | (1, 2, 3) Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, and Theo Vassilakis. Dremel: interactive analysis of web-scale datasets. Proc. VLDB Endow., 3(1-2):330–339, September 2010. doi:10.14778/1920841.1920886. |
| [23] | Curt Monash. Teradata and Netezza are doing MapReduce too. September 2009. URL: http://www.dbms2.com/2009/09/03/teradata-and-netezza-are-doing-mapreduce-too/. |
| [24] | (1, 2) Curt Monash. eBay’s two enormous data warehouses. April 2009. URL: http://www.dbms2.com/2009/04/30/ebays-two-enormous-data-warehouses/. |
| [25] | Curt Monash. eBay followup â Greenplum out, Teradata > 10 petabytes, Hadoop has some value, and more. October 2010. URL: http://www.dbms2.com/2010/10/06/ebay-followup-greenplum-out-teradata-10-petabytes-hadoop-has-some-value-and-more/. |
| [26] | Regina O. Obe and Leo S. Hsu. PostGIS in Action. Manning Publications Co., Greenwich, CT, USA, 2nd edition, 2015. ISBN 1617291390, 9781617291395. |
| [27] | Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel J. Abadi, David J. DeWitt, Samuel Madden, and Michael Stonebraker. A comparison of approaches to large-scale data analysis. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, SIGMOD ‘09, 165–178. New York, NY, USA, 2009. ACM. doi:10.1145/1559845.1559865. |
| [28] | Jeremiah Peschka. Facebook messaging - hbase comes of age. November 2010. URL: https://web.archive.org/web/20110215081418/http://nosqlpedia.com/wiki/Facebook_Messaging_-_HBase_Comes_of_Age. |
| [29] | Rob Pike, Sean Dorward, Robert Griesemer, and Sean Quinlan. Interpreting the data: parallel analysis with sawzall. Scientific Programming, 13:277, 2005. doi:10.1155/2005/962135. |
| [30] | Evan Schuman. At Wal-Mart, Worlds Largest Retail Data Warehouse Gets Even Larger. October 2004. URL: http://www.eweek.com/enterprise-apps/at-wal-mart-worlds-largest-retail-data-warehouse-gets-even-larger. |
| [31] | Y. Simmhan, R. Barga, C. van Ingen, M. Nieto-Santisteban, L. Dobos, N. Li, M. Shipway, A. S. Szalay, S. Werner, and J. Heasley. Graywulf: scalable software architecture for data intensive computing. In 2009 42nd Hawaii International Conference on System Sciences, 1–10. Jan 2009. doi:10.1109/HICSS.2009.235. |
| [32] | Mike Stonebraker, Daniel J. Abadi, Adam Batkin, Xuedong Chen, Mitch Cherniack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O’Neil, Pat O’Neil, Alex Rasin, Nga Tran, and Stan Zdonik. C-store: a column-oriented dbms. In Proceedings of the 31st International Conference on Very Large Data Bases, VLDB ‘05, 553–564. VLDB Endowment, 2005. URL: http://dl.acm.org/citation.cfm?id=1083592.1083658. |
| [33] | Alex S. Szalay, Gordon Bell, Jad Vandenberg, Alainna Wonders, Randal Burns, Dan Fay, Jim Heasley, Tony Hey, Maria Nieto-SantiSteban, Ani Thakar, Catharine van Ingen, and Richard Wilton. Graywulf: scalable clustered architecture for data intensive computing. Technical Report MSR-TR-2008-187, Microsoft, September 2008. URL: https://www.microsoft.com/en-us/research/publication/graywulf-scalable-clustered-architecture-for-data-intensive-computing/. |
| [34] | TokuTek. TokuDB: Scalable High Performance for MySQL and MariaDB Databases. April 2013. URL: https://web.archive.org/web/20130819012209/http://www.tokutek.com/wp-content/uploads/2013/04/Tokutek-White-Paper.pdf. |
| [35] | Jim Tommaney. Calpont: open source columnar storage engine for scalable mysql. April 2009. URL: https://web.archive.org/web/20090429121116/http://www.mysqlconf.com/mysql2009/public/schedule/detail/8997. |
| [36] | (1, 2) [DMTN-047]. Jim Tommaney, Jacek Becla, Kian-Tat Lim, and Daniel Wang. Tests with InfiniDB. 2011. LSST Data Management Technical Note. URL: https://dmtn-047.lsst.io |
| [37] | Tomas Ulin. Driving MySQL Innovation. Percona Live: MySQL Conference and Expo, April 2013. URL: https://www.youtube.com/watch?v=OpHTV59I1gs. |
| [38] | Florian M. Waas. Beyond conventional data warehousing — massively parallel data processing with greenplum database. In Malu Castellanos, Umesh Dayal, and Timos Sellis, editors, Business Intelligence for the Real-Time Enterprise: Second International Workshop, BIRTE 2008, Auckland, New Zealand, August 24, 2008, Revised Selected Papers, 89–96. Berlin, Heidelberg, 2009. Springer Berlin Heidelberg. URL: http://www.greenplum.com/resources/, doi:10.1007/978-3-642-03422-0_7. |
| [39] | (1, 2) Roberto V. Zicari. Objects in Space. February 2011. URL: http://www.odbms.org/blog/2011/02/objects-in-space/. |
| [40] | (1, 2) Gaia Collaboration, T. Prusti, J. H. J. de Bruijne, A. G. A. Brown, A. Vallenari, C. Babusiaux, C. A. L. Bailer-Jones, U. Bastian, M. Biermann, D. W. Evans, and et al. The Gaia mission. Astronomy and Astrophysics, 595:A1, November 2016. arXiv:1609.04153, doi:10.1051/0004-6361/201629272. |
| [41] | [LPM-17]. Ž. Ivezić and The LSST Science Collaboration. LSST Science Requirements Document. 2011. URL, https://ls.st/LPM-17. |
| [42] | R. Jedicke, E. A. Magnier, N. Kaiser, and K. C. Chambers. The next decade of Solar System discovery with Pan-STARRS. In G. B. Valsecchi, D. Vokrouhlický, and A. Milani, editors, Near Earth Objects, our Celestial Neighbors: Opportunity and Risk, volume 236 of IAU Symposium, 341–352. May 2007. doi:10.1017/S1743921307003419. |
| [*] | A private discussion of this experiment is available at https://listserv.lsstcorp.org/mailman/private/lsst-data/2012-November/310.html. The patches required for the MonetDB test can be found at https://github.com/lsst/qserv/tree/tickets/2426 |
| [†] | Original location of this 2010 report: https://dev.lsstcorp.org/trac/wiki/db/HiveExperiment |